


限られた生物分布データから、よりよい保護区を選定-環境情報を利用したデータ処理が有益となる条件を明らかに-
(筑波研究学園都市記者会、環境省記者クラブ、環境記者会同時配付)
| 令和2年1月10日(金) 国立研究開発法人 国立環境研究所 生物・生態系環境研究センター 主任研究員 石濱 史子 主任研究員 角谷 拓 元上級主席研究員 竹中 明夫 環境リスク・健康研究センター 主任研究員 横溝 裕行 |
|
国立環境研究所の石濱史子主任研究員らの研究グループは、保護区を選ぶ場合において、限られた生物の分布データを効果的に活用する方法を分析しました。 環境情報を利用した分布データの補完・補正処理(分布推定モデル※1)は、これまで十分な検討がされないまま、よりよい保護区の選定に有益として用いられてきました。しかし今回、「データの偏りが大きい」、「保護区が広くない」などの条件を満たす場合にのみ、本データ処理が有益であることを初めて明らかにしました。この研究結果により、利用が拡大しつつある分布推定モデルの適正な活用につながると期待されます。 本成果は、令和1年12月20日付で学術誌「PLOS ONE」に掲載されました。 |
1.背景と目的
保護区の設置は、生物多様性を保全するための主要な手段の1つであり、生物多様性条約の愛知目標11では、生物多様性を保全するために「2020年までに陸域の17%を効果的に管理された保護区とすること」が定められています。設定できる保護区の広さや効果的な管理を行える範囲が限られる中、保護区の配置や管理の実施場所を適切に選定できるかどうかは、生物多様性保全の成否にかかわります。
その一方で、保護区選定の基本情報となる生物の分布データは十分ではなく、調査範囲が限られている、調査地域が偏っている、などの課題があることが一般的です。このような分布データの不完全さを補うため、保護区選定の前に、広範囲で得られている環境情報に基づいて生物が生息する確率を推定し、データを補完・補正する処理(分布推定モデル※1、図1)を用いることが推奨されてきました。分布推定モデルは、近年の技術発展が著しく、生態学分野での利用が急速に増加しています。
しかし、分布推定モデル自体も、推定結果に誤差があるため、モデルを利用したデータ処理がよりよい保護区の選定につながらないこともあります。例えば、調査範囲が十分に広ければ、データ処理は必要ないでしょう。どのような条件であれば、モデル利用によるデータ処理が有益であるのかは、これまで明らかにされていませんでした。
そこで本研究では、保護区選定において、分布推定モデルによるデータ処理が推奨される条件を明らかにすることを目的として、分析を行いました。
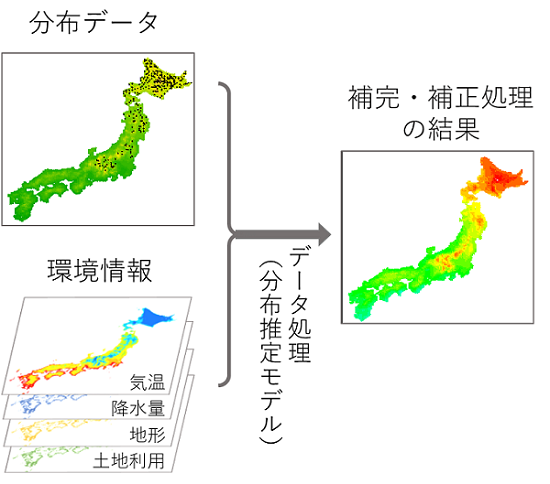
2.方法
分析の対象とする条件として、分布データの調査範囲の広さ、調査地域の偏り、保護区の広さに注目しました。様々な調査範囲や保護区の広さにおいて、保護区選定の前にデータ処理をした場合としない場合、それぞれで選ばれた保護区に含まれている生物種の数を比較し、より多くの種が含まれているほうがよい保護区を選定できたと評価しました。
しかし、現実の調査データは完全ではないため、保護区の中に含まれている生物種の数を正確に知ることはできず、このような評価が困難です。そこで、本研究では、コンピュータシミュレーションにより生成した仮想の生物の分布データを用いることで、生物種の正確な数を評価できるようにしました。ここでは、現実に近い分布データを生成できるよう、独自に考案したシミュレーション方法を用いました。
この仮想の分布データを用いて、調査範囲の広さ、調査地域の偏りの大きさ、保護区の広さの3つの条件を様々に変えながら、どのような条件でデータ処理を行ったほうがよりよい保護区が選定できるのかを分析しました。
データ処理に用いる分布推定モデルには多くの種類がありますが、よく用いられる一般化線形モデル、一般化加法モデル、ランダムフォレストの3つの種類のモデルを用いました。
3.結果と考察
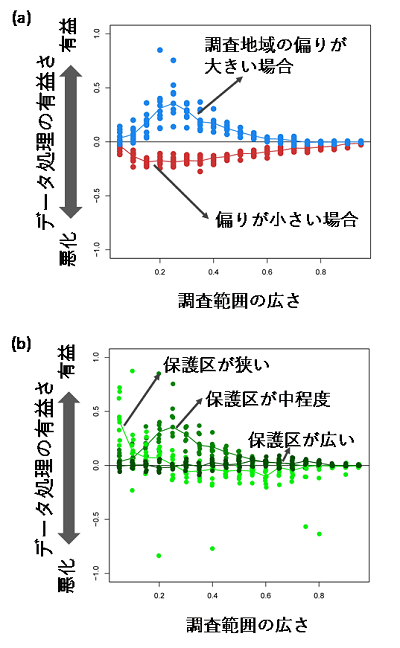
分析の結果、分布推定モデルによるデータ処理を行ったほうが、調査データをそのまま用いるよりよい保護区が選べたのは、以下の3つの条件が全て満たされる場合でした(図2)。
①保護区が広くない
②調査地域の偏りが大きい
③調査範囲が狭い~中程度
データ処理に用いるモデルの種類が違っても、これらの傾向は共通しており、3つの条件は一般性の高い結果であると考えられました。ただし、分布推定の精度が高いモデルほど、データ処理で改善がみられる条件が広くなる傾向がありました。
これらの結果は、保護区選定において、分布推定モデルによるデータ処理が推奨される条件を具体的に示すものであり、利用が拡大しつつある分布推定モデルの適正な活用につながると期待されます。
また、調査データに偏りがない場合には、データ処理が有益でないことも注目に値する結果です。本研究では、同じ広さの調査範囲であれば、偏りのない調査を実施するほうが、より多くの種を含む保護区を選定できることも明らかになっています。この結果は、調査を実施する場合には、調査地域の偏りが小さい調査設計とすることが、よい保護区を選定するための基本情報として非常に重要であることも示しています。
4.今後の展望
本研究は、現実的な群集構造を有する仮想の分布データをシミュレーションにより生成し、これまで正確な計数が不可能であった保護区の良さを評価可能にしたことで得られた成果です。本研究では、より多くの種が含まれているほうがよい保護区であるという設定で分析を行いました。これは、1種あたり1か所でも生息地が保護区に含まれていればよいとする、という単純化した設定です。今後、ある生物種の生息域のうち一定割合以上が保護区に含まれているかどうかなど、より効果的な保全ができる条件設定での分析を行うことで、保護区の選定技術の更なる向上につながると期待されます。
5.用語解説
※1 分布推定モデル (Species Distribution Modeling): 環境条件と生物の生育地点との相関関係を統計的に分析することにより、目的の生物種が生育する環境条件を解明したり、調査が行われていない場所の環境条件に基づいて当該生物種が生息している確率を推定したりする手法。生態ニッチモデル(Ecological Niche Modeling)ともいう。
6.研究助成
本研究の一部は環境研究総合推進費S9の助成により実施されました。
7.発表論文
【タイトル】Evaluation of the ecological niche model approach in spatial conservation prioritization
【著者】Fumiko Ishihama, Akio Takenaka, Hiroyuki Yokomizo, Taku Kadoya
【雑誌】PLOS ONE
【DOI】10.1371/journal.pone.0226971
【URL】https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0226971【外部サイトへ接続します】
※下線で示した著者が国立環境研究所所属です。
8.問い合わせ先
【研究に関する問い合わせ】
国立研究開発法人 国立環境研究所 生物・生態系環境研究センター
生物多様性評価・予測研究室 (主任研究員)石濱 史子
E-mail:ishihama(末尾に@nies.go.jpをつけてください)
TEL:029-850-2063
【報道に関する問い合わせ】
国立研究開発法人 国立環境研究所 企画部広報室
E-mail:kouhou0(末尾に@nies.go.jpをつけてください)
TEL:029-850-2308
関連新着情報
-
2025年11月18日
 生物の進化を島が支える
生物の進化を島が支える
-シマクイナが明かす、日本列島が大陸集団の存続を支える仕組み-(農政クラブ、農林記者会、林政記者クラブ、筑波研究学園都市記者会、北海道教育記者クラブ、文部科学記者会、科学記者会、環境省記者クラブ、環境記者会、千葉県政記者会、千葉民間放送テレビ記者クラブ同時配付) -
2025年9月17日流域の土地利用が湧水性魚類の分布に影響
—ホトケドジョウを指標に検証—(筑波研究学園都市記者会、環境省記者クラブ、環境記者会同時配付) -
2025年8月25日セミの大合唱から個別種を識別するAIを開発 —AIと音響シミュレーションで生物多様性モニタリングを効率化—(筑波研究学園都市記者会、環境省記者クラブ、環境記者会同時配付)
-
2025年7月3日\行動科学×生物多様性保全/
寄付型/金銭型インセンティブによって「いきもの写真」のアプリ投稿行動が変化 —ユーザー参加型で生物多様性データを集めていくために—(筑波研究学園都市記者会、環境省記者クラブ、環境記者会、大阪科学・大学記者クラブ、文部科学記者会、科学記者会同時配付) -
2025年4月30日生物群集はエネルギー地形の高低に従い変化する
—データ駆動型の生物多様性の変化予測を実現—(筑波研究学園都市記者会、環境省記者クラブ、環境記者会、文部科学記者会、科学記者会同時配付) -
2024年12月6日
 GBIFワークショップ「多様化する生物多様性調査とそのデータ」開催のお知らせ【終了しました】
GBIFワークショップ「多様化する生物多様性調査とそのデータ」開催のお知らせ【終了しました】
-
2024年11月25日気候変動緩和策による土地利用改変が大きい地域ほど
生物多様性の保全効果は低くなる
-植林とBECCSの大規模導入が
生物多様性に与える影響-(農政クラブ、農林記者会、林政記者クラブ、筑波研究学園都市記者会、京都大学記者クラブ、文部科学記者会、科学記者会、環境記者クラブ、環境記者会同時配付) -
2024年10月30日
 「生態毒性調査・研究を支える水生生物の飼育と分譲」記事を公開しました【国環研View DEEP】
「生態毒性調査・研究を支える水生生物の飼育と分譲」記事を公開しました【国環研View DEEP】
-
2024年8月7日その花は都市では咲かない
—都市化による雑草の繁殖形質の進化の検証—
(筑波研究学園都市記者会、環境省記者クラブ、環境記者会、文部科学記者会、科学記者会、千葉県政記者クラブ同時配付) -
2024年6月7日愛知目標の次のステージへ向けて:
「昆明・モントリオール生物多様性枠組」について特集しました(筑波研究学園都市記者会、環境省記者クラブ、環境記者会同時配付) -
2024年4月26日持続可能な発展に向けた対策は生物多様性の損失を抑え生態系サービスを向上させる(京都大学記者クラブ、草津市政記者クラブ、林政記者クラブ、農林記者会、農政クラブ、筑波研究学園都市記者会、文部科学記者会、科学記者会、環境省記者クラブ、環境記者会同時配付)
-
2024年3月19日気候変動と生物多様性にまたがる知見の整理
-IPCC報告書の解説資料·動画公開と関連イベント開催-【終了しました】(筑波研究学園都市記者会、環境省記者クラブ、環境記者会同時配付) -
2023年11月30日殺虫剤と水田の水温上昇がトンボ類に与える影響を解明
温暖化に起因する水温上昇は殺虫剤による生態リスクを高める可能性
(大阪科学・大学記者クラブ、農政クラブ、農林記者会、文部科学記者会、科学記者会、環境記者会、環境問題研究会、東大阪市政記者クラブ、奈良県政・経済記者クラブ、奈良県文化教育記者クラブ、筑波研究学園都市記者会、弘前記者会同時配付) -
2023年10月4日生き物の分布推定ツール「オープンSDM」の公開
—誰もが生物種分布モデルを学び使うことを支援するツール—(筑波研究学園都市記者会、環境省記者クラブ、環境記者会同時配付) -
2023年9月26日昆明・モントリオール生物多様性枠組の達成に向けた
全球生物多様性観測システム(GBiOS)の構築(筑波研究学園都市記者会、環境省記者クラブ、環境記者会、岐阜県政記者クラブ、文部科学記者会、科学記者会同時配付) -
2023年9月19日価値観の危機:生物多様性・異常気象を招いた価値観の偏り
『Nature』誌にIPBES研究成果論文掲載(筑波研究学園都市記者会、環境省記者クラブ、環境記者会同時配付) -
2023年8月1日気候変動の総費用
—生物多様性や人間健康などの非市場価値と2℃目標—(筑波研究学園都市記者会 環境記者会 環境問題研究会 農政クラブ 農林記者会 農業技術クラブ 文部科学記者会 科学記者会 茨城県政記者クラブ同時配付) -
2023年6月22日細胞のタイムカプセルで絶滅危惧種の多様性を未来に残す
—国⽴環境研究所、絶滅危惧種細胞保存事業を拡⼤
沖縄の次は北海道へ(筑波研究学園都市記者会、環境省記者クラブ、環境記者会、沖縄県政記者クラブ、北海道庁道政記者クラブ、釧路総合振興局記者クラブ同時配付) -
2023年4月24日行動経済学の力で保全資金の効果的な獲得を目指す(筑波研究学園都市記者会、環境省記者クラブ、環境記者会、⽴川市政記者クラブ、⽂部科学省記者会同時配付)
-
2023年4月18日牧野富太郎博士ゆかりの水草ムジナモ(絶滅危惧IA類)
国内自生地を発見(筑波研究学園都市記者会、環境省記者クラブ、環境記者会、文部科学記者会、科学記者会、新潟県政記者クラブ、金沢経済記者クラブ同時配付) -
2022年12月14日お米に生物多様性の価値を!ラベル認証で保全を促進
認証と保全象徴種の明示で生物多様性保全米の差別化の可能性(文部科学記者会、科学記者会、環境省記者クラブ、環境記者会、宮城県政記者会、東北電力記者会、北海道教育庁記者クラブ、筑波研究学園都市記者会同時配付) -
2022年11月18日なぜ象牙需要は減ったのか? 要因に迫る新たな研究成果
-
2022年11月10日カエルが多い水田はどこにあるのか?
関東平野の水田に生息するカエル類の分布を鳴き声で推定 -
2022年10月7日住宅地に残る「空き地」、草原としての
歴史の長さと生物多様性の関係を解明(環境記者会、環境問題研究会、筑波研究学園都市記者会同時配布) -
2022年8月10日サステナクラフト、国立環境研究所、一橋大学が
質の高い森林由来のカーボンクレジット創出に向けた共同研究を開始
〜NEDOの研究開発型スタートアップ支援事業に採択〜(筑波研究学園都市記者会、環境省記者クラブ、環境記者会同時配布) -
2022年6月17日産学連携の共同研究成果を発表、国際学術誌に掲載—多様な虫の鳴き声がリラックス効果をもたらすことを確認—
-
2022年3月31日ユスリカからのメッセージ
顕微鏡下で識別する環境情報
国立環境研究所『環境儀』第84号の刊行について(筑波研究学園都市記者会、環境記者会、環境省記者クラブ同時配付) -
2022年3月23日ヒトと共に去ったチョウたち
~「廃村」から見た人口減少時代の生物多様性変化~(筑波研究学園都市記者会、環境省記者クラブ、環境記者会、文部科学記者会、科学記者会、大学記者会(東京大学)同時配付) -
2022年3月1日世界最大の花・ラフレシアの新産地とその生態の解明
~地域社会による生息域内保全の促進に期待~(筑波研究学園都市記者会、環境省記者クラブ、環境記者会、京都大学記者クラブ、文部科学記者会、科学記者会、横須賀市政記者会同時配付) -
2021年12月3日—38ヵ国95名の研究者が提言—
淡水域の生物多様性減少を救う15の優先課題(筑波研究学園都市記者会、環境省記者クラブ、環境記者会、文部科学記者会、科学記者会同時配付) -
2021年10月25日森林を守ることが海の生物多様性を守ることにつながる(京都大学記者クラブ、文部科学記者会、科学記者会、環境省記者クラブ、環境記者会、筑波研究学園都市記者会、北海道教育庁記者クラブ同時配付)
-
2021年9月7日その靴、掃除しました?高山域への外来植物の持ち込みの
抑止は訪問者の無知識・無関心ではなく無行動が障壁に(文部科学記者会、科学記者会、府中市政記者クラブ、富山県政記者クラブ、筑波研究学園都市記者会、環境省記者クラブ、環境記者会同時配付) -
2020年11月13日人が去ったそのあとに~人口減少時代の国土デザインに向けた生物多様性広域評価~
国立環境研究所研究プロジェクト報告の刊行について
(お知らせ)(筑波研究学園都市記者会、環境省記者クラブ、環境記者会同時配付) -
2020年10月15日森のシカは、夏は落ち葉を、冬は嫌いな植物を食べて生きぬく ~シカ糞の遺伝情報から、シカの食べる植物の季節変化を解明~(筑波研究学園都市記者会、環境省記者クラブ、環境記者会、兵庫県政記者クラブ、京都大学記者クラブ、文部科学記者会、科学記者会同時配布)
-
2020年9月10日生物多様性の損失を食い止め回復させるための道筋-自然保護・再生への取り組みと食料システムの変革が鍵-(京都大学記者クラブ、草津市政記者クラブ、林政記者クラブ、農林記者会、農政クラブ、筑波研究学園都市記者会、文部科学記者会、科学記者会、環境省記者クラブ、環境記者会同時配布)
-
2020年5月14日生物多様性ビッグデータで
日本全土の木本植物の個体数を推定
(筑波研究学園都市記者会、環境省記者クラブ、環境記者会、沖縄県政記者クラブ、文部科学記者会同時配付) -
2020年2月6日最新のデータとモデルから
森林内の放射性セシウムの動きを将来予測
-森林の中での動きが平衡状態に近づいている-(林政記者クラブ、農林記者会、農政クラブ、筑波研究学園都市記者会、環境省記者クラブ、環境記者会、福島県政クラブ同時配付) -
2019年12月26日「GMO(遺伝子組換え生物)アンダーザブリッジ
~除草剤耐性ナタネの生物多様性影響調査~」
国立環境研究所「環境儀」第75号の刊行について(筑波研究学園都市記者会、環境記者会、環境省記者クラブ同時配付) -
2019年12月24日生物多様性保全のための科学的根拠を集約
科学誌サイエンスに総説掲載(千葉大学のサイトに掲載) -
2019年12月20日「東南アジア熱帯林における高解像度3次元モニタリングによる生物多様性・機能的多様性の評価手法の開発 平成28~30年度」
国立環境研究所研究プロジェクト報告の刊行(筑波研究学園都市記者会、環境省記者クラブ、環境記者会同時配付) -
2019年12月3日生物多様性保全と温暖化対策は両立できる
-生物多様性の損失は気候安定化の努力で抑えられる-(林政記者クラブ、農林記者会、農政クラブ、筑波研究学園都市記者会、京都大学記者クラブ、環境省記者クラブ、環境記者会同時配付) -
2019年8月2日製鉄が野生動物に与えた影響は千年紀を超えて残る
-生物と遺跡の地理的分布から見えたこと-(筑波研究学園都市記者会、環境省記者クラブ、環境記者会等同時配布) -
2018年4月12日「生物多様性と地域経済を考慮した亜熱帯島嶼環境保全策に関する研究平成25~27年度」
国立環境研究所研究プロジェクト報告の刊行について(お知らせ)(筑波研究学園都市記者会、環境省記者クラブ、環境記者会同時配付) -
2018年3月2日第3回NIES国際フォーラム/3rd International Forum on Sustainable Future in Asia
の開催報告について(お知らせ)
(筑波研究学園都市記者会、環境省記者クラブ、環境記者会同時配付) -
2018年1月25日第三回NIES国際フォーラム/3rd International Forum on Sustainable Future in Asia
の開催について
(お知らせ)【終了しました】(筑波研究学園都市記者会、環境記者会、環境省記者クラブ同時配付) -
2017年10月18日
タケ、北日本で分布拡大のおそれ
~里山管理の脅威になっているモウソウチクとマダケ(産業管理外来種)の生育に適した環境は温暖化で拡大し、最大500km北上し稚内に到達~(宮城県政記者会、科学記者会、文部科学記者会、大学記者会、京都大学記者クラブ、環境省記者クラブ、環境記者会、筑波研究学園都市記者会、気象庁記者クラブ同時配付) -
2017年6月30日
水田消滅による里地里山の変貌を地図化
—水域と陸域の違いを考慮した農地景観多様度指数の開発(筑波研究学園都市記者会、環境省記者クラブ、福島県政記者クラブ同時配付) -
2017年2月28日「生物多様性研究プログラム」
国立環境研究所研究プロジェクト報告の刊行について
(お知らせ)
(筑波研究学園都市記者会、環境省記者クラブ同時配付) -
2017年1月24日第32回全国環境研究所交流シンポジウム
「多様化する環境問題を知る・束ねる」の開催について【終了しました】(筑波研究学園都市記者会、環境省記者クラブ同時配付) -
2017年1月10日第二回NIES国際フォーラム/2nd International Forum on Sustainable Future in Asiaの
開催について
(お知らせ)【終了しました】(環境省記者クラブ、筑波研究学園都市記者会同時配付) -
2016年12月14日第13回日韓中三カ国環境研究機関長会合(TPM13)の結果について
(お知らせ)
(筑波研究学園都市記者会配付) -
2016年11月7日分布が狭い植物ほど、自然保護区で守れない!?
~無計画な保護区設置が導く絶滅への悪循環~
(お知らせ)
(筑波研究学園都市記者会、環境省記者クラブ、文科省記者会、府中市政記者クラブ同時配布)
-
2016年10月17日「環境展望台」をリニューアルしました
-
2016年10月17日第13回日韓中三カ国環境研究機関長会合(TPM13)の開催について(お知らせ)【終了しました】
(筑波研究学園都市記者会、環境省記者クラブ同時配付) -
2016年2月12日第1回NIES国際フォーラム『アジアにおける持続可能な未来:熱望を行動に換えて』
(1st NIES International Forum “Sustainable Future in Asia: Converting Aspirations to Actions”)
の開催報告について(お知らせ)
(環境省記者クラブ、筑波研究学園都市記者会同時配付)
-
2015年10月27日第12回日韓中三カ国環境研究機関長会合(TPM12)の開催について(お知らせ)【終了しました】(筑波研究学園都市記者会、環境省記者クラブ同時配付)
-
2015年7月6日公開シンポジウム開催案内
「ネオニコチノイド系農薬と生物多様性〜
何がどこまで分かっているか? 今後の課題は何か?」【終了しました】(筑波研究学園都市記者会、環境省記者クラブ同時配付) -
2014年11月4日第11回日韓中三カ国環境研究機関長会合(TPM11)の開催について(お知らせ)【終了しました】(筑波研究学園都市記者会、環境省記者クラブ、川崎市政記者クラブ同時配付)
-
2014年7月10日写真&ポスター展「花咲くボルネオ熱帯の森 -数年に一度の不思議な現象-」開催のお知らせ【終了しました】
-
2014年6月26日シンポジウム「DNAから生物多様性を紐解く~データベース整備から次世代シーケンサー活用まで~」開催のお知らせ【終了しました】
関連研究報告書
-
 2018年2月28日生物多様性と地域経済を考慮した亜熱帯島嶼環境保全策に関する研究国立環境研究所研究プロジェクト報告 SR-127-2017
2018年2月28日生物多様性と地域経済を考慮した亜熱帯島嶼環境保全策に関する研究国立環境研究所研究プロジェクト報告 SR-127-2017
-
 2017年2月28日生物多様性研究プログラム(重点研究プログラム)
2017年2月28日生物多様性研究プログラム(重点研究プログラム)
平成23~27年度国立環境研究所研究プロジェクト報告 SR-116-2016 -
 2010年6月19日国立環境研究所 公開シンポジウム2010 4つの目で見守る生物多様性−長い目、宙(そら)の目、ミクロの目、心の目− 国立環境研究所研究報告 R-204-2010
2010年6月19日国立環境研究所 公開シンポジウム2010 4つの目で見守る生物多様性−長い目、宙(そら)の目、ミクロの目、心の目− 国立環境研究所研究報告 R-204-2010
-
 2006年12月28日生物多様性の減少機構の解明と保全プロジェクト(終了報告)
2006年12月28日生物多様性の減少機構の解明と保全プロジェクト(終了報告)
平成13〜17年度国立環境研究所特別研究報告 SR-72-2006 -
 2004年3月31日ため池の評価と保全への取り組み国立環境研究所研究報告 R-183-2004
2004年3月31日ため池の評価と保全への取り組み国立環境研究所研究報告 R-183-2004
-
 2003年11月28日生物多様性の減少機構の解明と保全プロジェクト(中間報告)
2003年11月28日生物多様性の減少機構の解明と保全プロジェクト(中間報告)
平成13〜14年度国立環境研究所特別研究報告 SR-57-2003 -
 2003年1月31日Global Taxonomy Initiative in Asia(アジアにおける世界分類学イニシアティブ) 国立環境研究所研究報告 R-175-2003
2003年1月31日Global Taxonomy Initiative in Asia(アジアにおける世界分類学イニシアティブ) 国立環境研究所研究報告 R-175-2003