


絶滅危惧植物の分布推定 −“いない”という情報をどう扱う?−
●特集 生物多様性● 【研究ノート】
石濱 史子
保全を行うための経済的・人的資源は無限ではありません。限りあるこれらの資源を使って効率的に保全を行うためには、どこの地域が保全対策を必要としている生物が多いのか、全国スケールでの検討が必要になります(優先的な保護区の選択手法については本号p.6を参照)。このような検討を行うためには、保護の対象となりうる生物がどこに生育しているかをまず知る必要があります。けれども、日本には維管束植物(花が咲く植物とシダの仲間)が約7000種も生育しており、さらにそのうちの約1/4もの種が絶滅危惧種とされています。これほどの数の植物の分布を日本全国、くまなく調査するのは、容易なことではありません。そこで活用されているのが、気象条件や地形などの環境情報に基づいて、対象とする生物が分布する確率を推定する“分布推定モデル”です。分布推定モデルを用いることによって、調査が不十分な地域に潜在的な生息場所があるかどうかを推定することができます。また、将来、気候変動や開発によって土地利用が変化した場合に、生物の分布がどのような影響を受けるかの予測などにも応用可能です。
分布推定モデルを作るときには、地点ごとの気象条件・地形・土地利用などの環境情報に加えて、“分布していることが既にわかっている地点(在地点)“と“分布していない地点(不在地点)”のデータがある程度の数そろっていることが必要です。在地点の情報からは、その地点の環境が対象とする生物の生育に適した環境であるということはわかりますが、では、それ以外の環境は不適なのかどうかはわかりません。この不適な環境の情報を与えるのが、不在地点の情報なのです。たとえば、公園の池にコイがいるという情報だけでなく、芝生や植え込みにはコイがいない、という情報があって初めてコイは水生の生物であるということがわかります。
環境情報は、気象庁や国土交通省を始めとして、行政や研究機関が公表している様々なデータがありますので、比較的容易に入手できます。生物の既知の分布地点の情報には、博物館等の標本情報がよく用いられます。ここで、最も収集するのが難しいのが“分布していない地点”の情報です。標本があれば、そこに生育していることは明らかですが、では、標本がない地域には本当に生育していないのでしょうか?この場合、2つの可能性があります。調査をしたけれども生育していなかった可能性と、そもそもその場所で調査が行われなかった可能性です。前者であれば、信頼のおける不在情報ですが、後者の場合、在地点か不在地点かは不明です。困ったことに、標本情報では、この2つの可能性の区別がつきません。標本情報のような、在地点に関しては信頼がおけるが不在地点の情報がないデータは“在のみ”データと呼ばれ、以前から分布推定モデリングの際の大きな問題として認識されてきました。
在のみデータから分布推定モデルを作成する場合、不在地点をどのように工面するか。不在情報そのものはないので、“在情報のない地点”をなんとか活用するしかありません。在情報のない地点からランダムもしくは一定のルールに従って選んだ地点を、仮に不在地点として扱う方法は、偽不在(pseudo absence)と呼ばれます。偽不在地点の選び方としては、大きく分けて3通り考えられます。1つは、とにかく在情報のない地点は全て不在地点として扱うというもの。2つ目は、在情報のない地点の中から、一定の数の偽不在地点をランダムに選ぶというもの。3つ目は、対象とする種の在情報はないけれども、近縁な種の在情報がある地点を使うというもの。隣の公園の池にコイがいるという報告はないけれども、キンギョがいるという報告はあるから、少なくとも調査は行われて、それでもコイは発見されなかったのだと考えるわけです。
3つの方法はそれぞれ、利点と欠点があります。1つ目の方法は、対象としている地域の環境条件を全てカバーできるという利点があります。その一方で、あたかも確実な不在情報が大量にあるような扱いをしてモデルを作ってしまうので、調査が行われなかっただけで本当は生育に適した環境条件まで、不適な環境であると誤って判定されてしまいがちになります。
2つ目の方法は、不在地点数が多くなりすぎないようにコントロールすることができるという利点があります。在地点数とのバランスを考えて、在地点の3倍程度の数の不在地点を選ぶ、というのが経験的によく使われています。ただし、あくまでもランダムに選ぶので、本当は生育に適しているにも関わらず調査が入らなかっただけの場所も、調査しても生育が確認されなかった本当に不適な場所と同じ確率で選ばれます。
3つ目の方法は、調査が入っている可能性が高い場所を選ぶので、2つ目の方法を改善したベストな方法のように思えます。けれども、この方法も欠点があって、常識的に考えても目的の生物が生育しているとは思われないような環境条件の場所が、不在地点として使われなくなってしまうという問題があります。たとえばコイもキンギョもブラックバスも芝生では観察されないから、芝生は偽不在地点には選ばれなくなります。こうすると、モデルを作る上では、芝生はコイの生息に“不適切な環境条件”ではなく、“調査が行われていなくて、適しているとも不適であるとも判断できない環境条件”として扱われてしまうことになるのです。
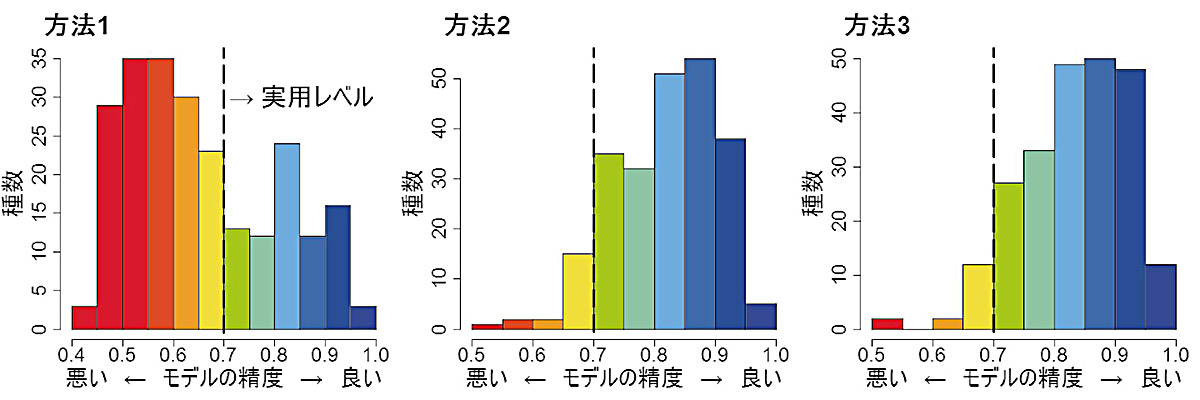
以上の3つの偽不在情報の選び方がモデルの推定精度にどのように影響するか、日本の維管束絶滅危惧植物のデータを用いて、比較を行いました(図)。図の水平軸はAUCという指標で、分布推定モデルの精度の評価によく用いられます。0から1までの値をとり、大きいほど精度がよく、0.7以上であれば実用的とされています。垂直軸は、それぞれのAUCの値をとった種数です。まず、方法1でAUCの値が0.7を下回る種が極端に多いことがわかります。あたかも確実な不在情報がたくさんあるかのように無闇にデータを与えると、適した環境まで不適と強く判定してしまうようになるためと考えられます。これに対して、方法2と3はほぼ変わりなくよい成績を収めています。解析を行った当時、3の方法が優れているという報告が相次いでいたので、これは意外な結果でした。2の方法は生育に適した環境も偽不在地点に選んでしまう欠点はあるものの、幅広い環境条件にまたがる地点を選ぶことの利点が欠点を上回ったものと思われます。今回は日本の絶滅危惧植物のデータでの検討でしたが、データの特徴によっては、2と3いずれかの方法がより優れている場合もあるかも知れません。今後は、日本の固有植物やアジア太平洋地域の植物の分布情報などでも2と3の方法の比較を行なってみたいと考えています。
分布推定モデルは、十分な分布情報がない場合に情報を補完するための便利なツールとして広く使われていますが、不在情報の扱いひとつで大きく結果が変わってしまう危うさも持っています。今回ご紹介したような検討を重ねることで、信頼のおける推定ができるモデルを構築し、よりよい保全策の設計に貢献したいと思っています。
生物多様性評価・予測研究室 主任研究員)
執筆者プロフィール:

生後5ヶ月になる娘の子育てに奮闘中です。絶滅危惧植物の保全を研究テーマとしていますが、もう1つ守るものが増えたなぁと感じています。
目次
関連新着情報
-
2025年11月18日
 生物の進化を島が支える
生物の進化を島が支える
-シマクイナが明かす、日本列島が大陸集団の存続を支える仕組み-(農政クラブ、農林記者会、林政記者クラブ、筑波研究学園都市記者会、北海道教育記者クラブ、文部科学記者会、科学記者会、環境省記者クラブ、環境記者会、千葉県政記者会、千葉民間放送テレビ記者クラブ同時配付) -
2025年2月6日野生生物取引の規制、意図せぬ波及効果が明らかに
—規制対象外の種の取引量増加を示唆
(筑波研究学園都市記者会、環境省記者クラブ、環境記者会、大阪科学・大学記者クラブ、文部科学記者会、科学記者会、徳島県教育記者クラブ同時配付) -
2024年12月3日国環研が支援する初のベンチャー企業設立
-国環研が開発した鳥インフルエンザウイルス病原性の
迅速判定技術を活用-
(筑波研究学園都市記者会、環境記者クラブ、環境記者会、農政クラブ、農林記者会、経済産業記者会、経産省ペンクラブ同時配付) -
2023年10月4日生き物の分布推定ツール「オープンSDM」の公開
—誰もが生物種分布モデルを学び使うことを支援するツール—(筑波研究学園都市記者会、環境省記者クラブ、環境記者会同時配付) -
2023年10月3日絶滅危惧鳥類ヤンバルクイナの免疫系の活性化に関わる遺伝子の機能喪失を発見
—ヤンバルクイナの感染症リスク評価・対策への新知見—(筑波研究学園都市記者会、環境記者会、環境問題研究会、沖縄県政記者クラブ、岩手県政記者クラブ、岩手県庁教育記者クラブ、文部科学記者会、科学記者会、日経バイオテク同時配付) -
2023年8月29日
 クラウドファンディング第2弾目標達成の御礼
クラウドファンディング第2弾目標達成の御礼
-
2023年6月22日細胞のタイムカプセルで絶滅危惧種の多様性を未来に残す
—国⽴環境研究所、絶滅危惧種細胞保存事業を拡⼤
沖縄の次は北海道へ(筑波研究学園都市記者会、環境省記者クラブ、環境記者会、沖縄県政記者クラブ、北海道庁道政記者クラブ、釧路総合振興局記者クラブ同時配付)
関連記事
関連研究報告書
-
 2017年10月10日絶滅過程解明のための絶滅危惧種ゲノムデータベース構築国立環境研究所研究プロジェクト報告 SR-124-2017
2017年10月10日絶滅過程解明のための絶滅危惧種ゲノムデータベース構築国立環境研究所研究プロジェクト報告 SR-124-2017
-
 2009年12月25日湿地生態系の時空間的不均一性と生物多様性の保全に関する研究(特別研究)
2009年12月25日湿地生態系の時空間的不均一性と生物多様性の保全に関する研究(特別研究)
平成18〜20年度国立環境研究所特別研究報告 SR-89-2009 -
 2008年12月26日鳥類体細胞を用いた子孫個体の創出(特別研究)
2008年12月26日鳥類体細胞を用いた子孫個体の創出(特別研究)
平成17〜19年度国立環境研究所特別研究報告 SR-81-2008 -
 2006年12月28日生物多様性の減少機構の解明と保全プロジェクト(終了報告)
2006年12月28日生物多様性の減少機構の解明と保全プロジェクト(終了報告)
平成13〜17年度国立環境研究所特別研究報告 SR-72-2006 -
 2003年11月28日生物多様性の減少機構の解明と保全プロジェクト(中間報告)
2003年11月28日生物多様性の減少機構の解明と保全プロジェクト(中間報告)
平成13〜14年度国立環境研究所特別研究報告 SR-57-2003